VMware Storage I/O Control breaks Storage vMotion
TLDR: If you are running a large storage vMotion (in my case: 1TB+) and it hangs about 30min into the operation and at the same time device latency per host goes through the roof and storage I/O control activity hits 100. Try turn off Storage I/O control on the target storage. VM size and timing will of course all be in relation to your environment. I was migrating from SAS to a much faster tiered solution.
So I’ve been busy with a migration project which involved, amongst other things, moving the customer from a Dell PowerVault MD3420 (SAS) to a shiny new Dell SCv3020 with a mix of SSD and NLSAS (iSCSI). One of the cool things with the SCv3020 unit is QoS profiles, which allow you to create storage performance tiers you can apply to LUNs. This is pretty basic, giving you the choice of priority as well as cap on throughput. It looked simple enough so I thought so let’s give it a whirl. I did quite an extensive amount testing with IOMeter before taking into production and on a 80/20 R/W profile as soon as the throughput cap was reached you could see the introduction of latency taking place to keep the throughput in check. So I was confident this worked as I expected. This gave the customer the ability to apply profiles inside the storage unit and allow it to take care of throughput along with the other clever hot / cold data progression stuff.
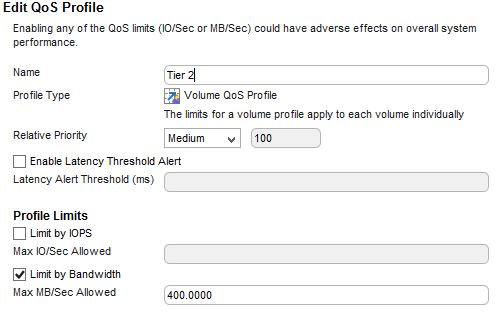
QoS profile example
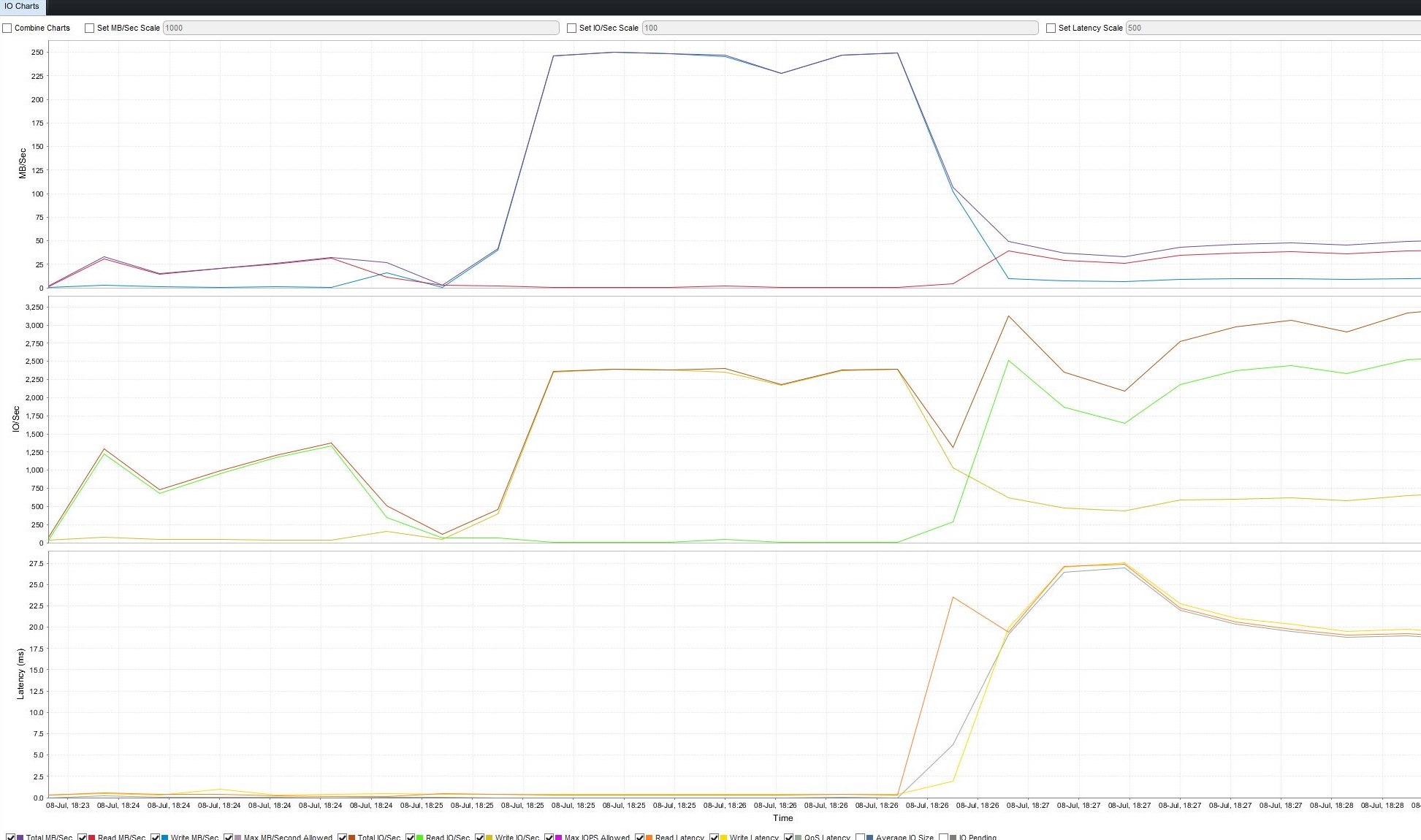
Example of QoS introducing latency to maintain the imposed limits. At 18:26 you can see latency shoot up where I applied a 50MB/s QoS profile. The grey line show QoS induced latency.
When I started migrating workloads I got all the smaller VMs out the way early, it was when I got to the larger VMs that I first started noticing issues. I had a VM with a 1.5TB disk which I kicked off before going to bed. It ran for probably 4 hours and then reported as failed. The second time I tried it (overnight again) it was at 40% early the following morning. I was mostly stuck in meetings that morning, but when I surfaced my colleagues started circling (you know that look!).
Customer was complaining about “slowness” on a particular VM in the same environment (not the one being moved). We could see from the VM metrics the disk latency was really high. I checked the SCv3020 and the latency on the LUN was much higher that the others, often hitting between 50-100ms. So my first action was to cancel the storage vMotion (which was still stuck on 40%). It certainly looked like it made things better but I still wasn’t happy with the latency on the SCv3020 for the datastore (LUN). Digging into more of the VMware metrics at the datastore level also showed much higher latency on the datastore to which the vMotion was running.
We then started digging into each individual VM with high I/O. One of them was a CentOS box with some webapp and MySQL workloads which was in a bit of an unhappy state. We’d discovered that due to the I/O issues VMware Tools heartbeats had not been received for some VMs and HA had rebooted them, this happened to be one of them. Some basic troubleshooting on MySQL and related services didn’t yield positive results (services failing to stop or start) so I rebooted it which resolved the problem. Next up was a generally busy MSSQL box which had really crazy high read activity going on. Eventually DB admin restarted the MSSQL service and it returned to normal. The reason I mention this is to highlight the impact I/O degradation can have on OS and applications. Sometimes you just have to restart/reboot after resolving the I/O issue. I’ve also often seen I/O delays result in high CPU load, so keep an eye out for that. I did also during this troubleshooting notice the Storage I/O control metrics and that only the datastore that was performing poorly was impacted by Storage I/O control activity. The reading I had done suggested it was a good thing in that it reigned in the noisy VMs. So I noted it, but didn’t dig further.
So with the storage vMotion killed and the noisy VMs silenced I carried on monitoring VMware and the SCv3020. I still wasn’t happy with the latency I was seeing on the SCv3020. The throughput hardly hit 100MB/s yet I could see latency was being introduced by QoS. So on a hunch I removed the QoS restriction and suddenly the latency started dropping off. My suspicion being that the relative priority also had some impact on when QoS latency kicks in. Relative Priority is used to “define their relative priority during times of congestion”. Which is what I thought it was for, so it didn’t make sense to me that turning it off made any difference as there was still plenty of throughput headroom. At this point everything was calm again and there was some time to reflect and discuss some findings so far with my colleagues where one surmised that perhaps it was possible that the QoS of the SCV3020 and VMware Storage I/O Control could be working against each other. Mmmmmmm.
That evening I had another stab at it with all my monitoring metrics ready and the QoS profile removed. I started with a 500GB VM which completed in 34min without any latency issues. So I kicked off the 1.5TB VM again. Things looked very good initially, but about 30min I could see the device latency in VMware climbing and the storage vMotion was stuck at 40%. The SCV3020 was not showing any latency issues, but it did show a dramatic drop in throughput. I then again paid attention to storage I/O control activity and its relation to the device latency and these corresponded quite clearly. As I/O control started hitting 100 so did the device latency climb in VMware. Given my experience with QoS on the SCV3020 I thought “aha!” and disabled storage I/O control. Things recovered quite quickly after that, device latency started dropping, the throughput shot up and the storage vMotion resumed. Storage vMotion completed in about 1h50m (including the troubleshooting time that it was stalled).
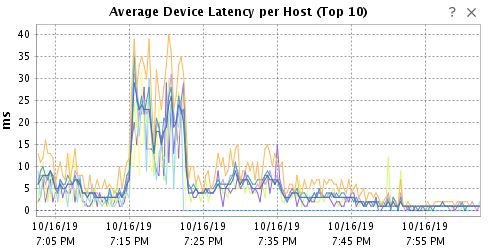
Example of high device latency caused by storage I/O control. 7:15PM was about 30min into my storage vMotion.
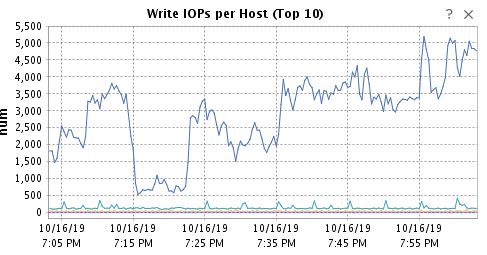
Corresponding Write IOPs. Latency goes up, throughput tanks.
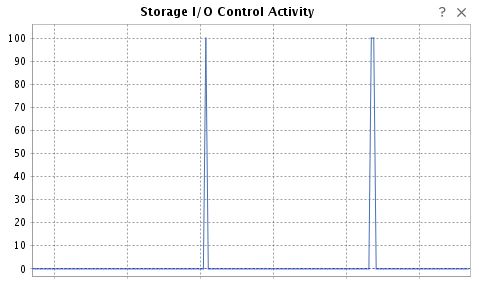
Example of Storage I/O control Activity (tabletop at 100 is bad)
So all-in-all a fun learning experience and a chance to understand some of the performance metrics a bit better, but most importantly the reminder that the impact of overlapping functionality does need to be considered during implementation. For now I’m going to leave VMware storage I/O control disabled and let the SCv3020 QoS do the work.
Note: Storage I/O control is enabled when you create a storage cluster, which admittedly I hadn’t paid much attention to at the time. I had however specifically set Storage DRS to manual because the SCv3020 documentation will tell you that if you don’t it will hamper its ability to profile your hot and cold data. Essentially if its done the work to profile the data and DRS moves the disk elsewhere it has to profile it all over again.